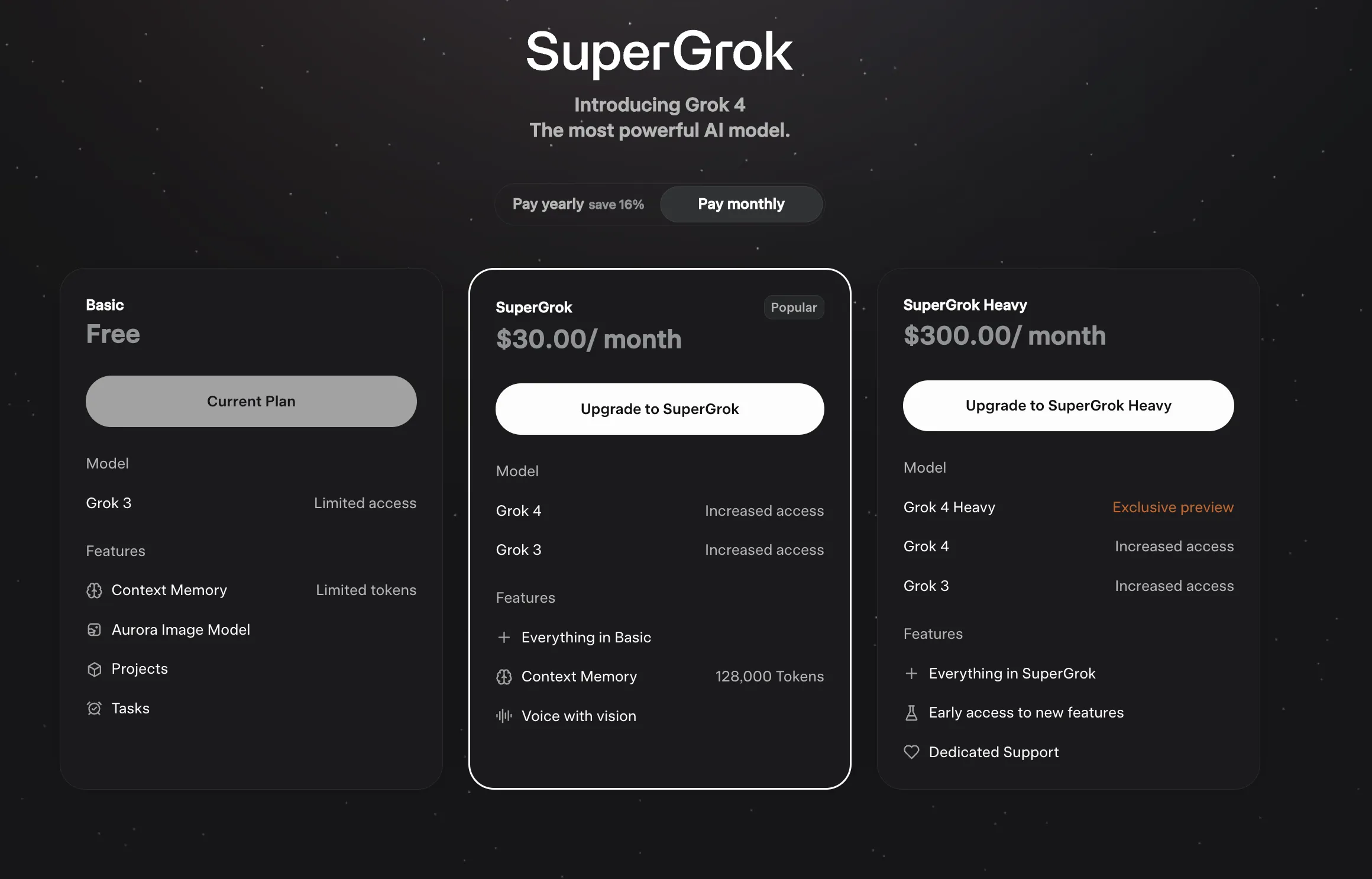
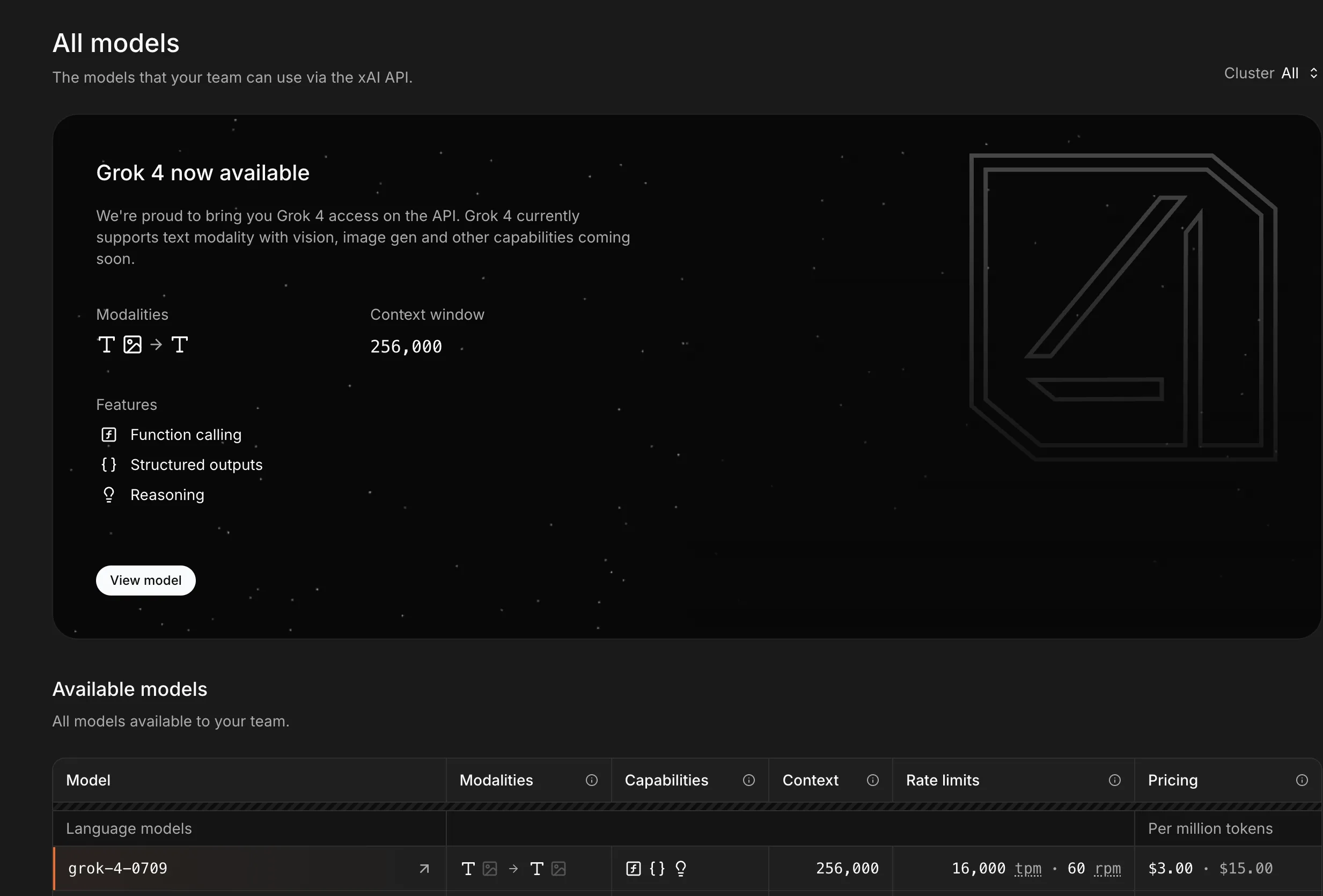
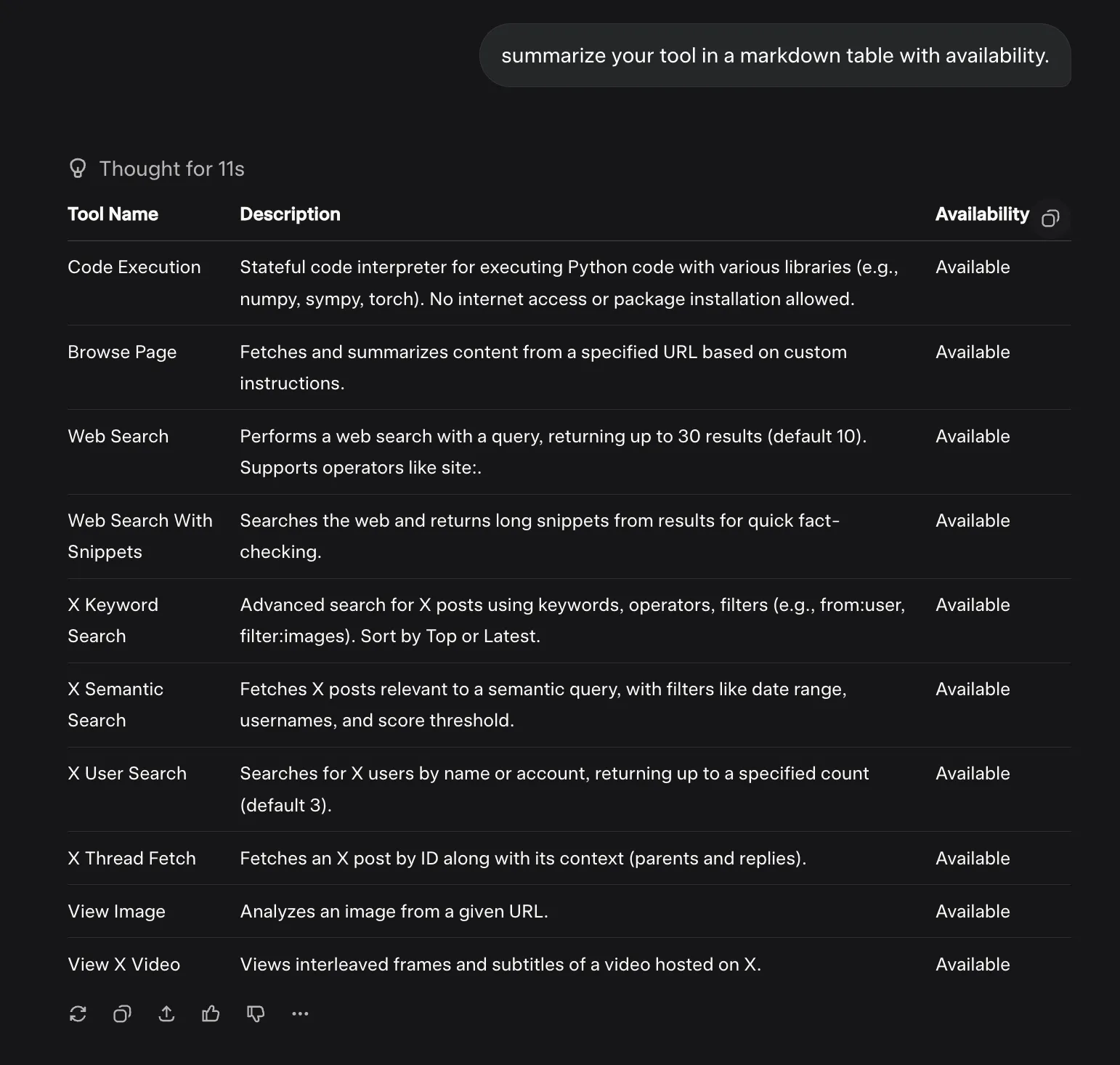
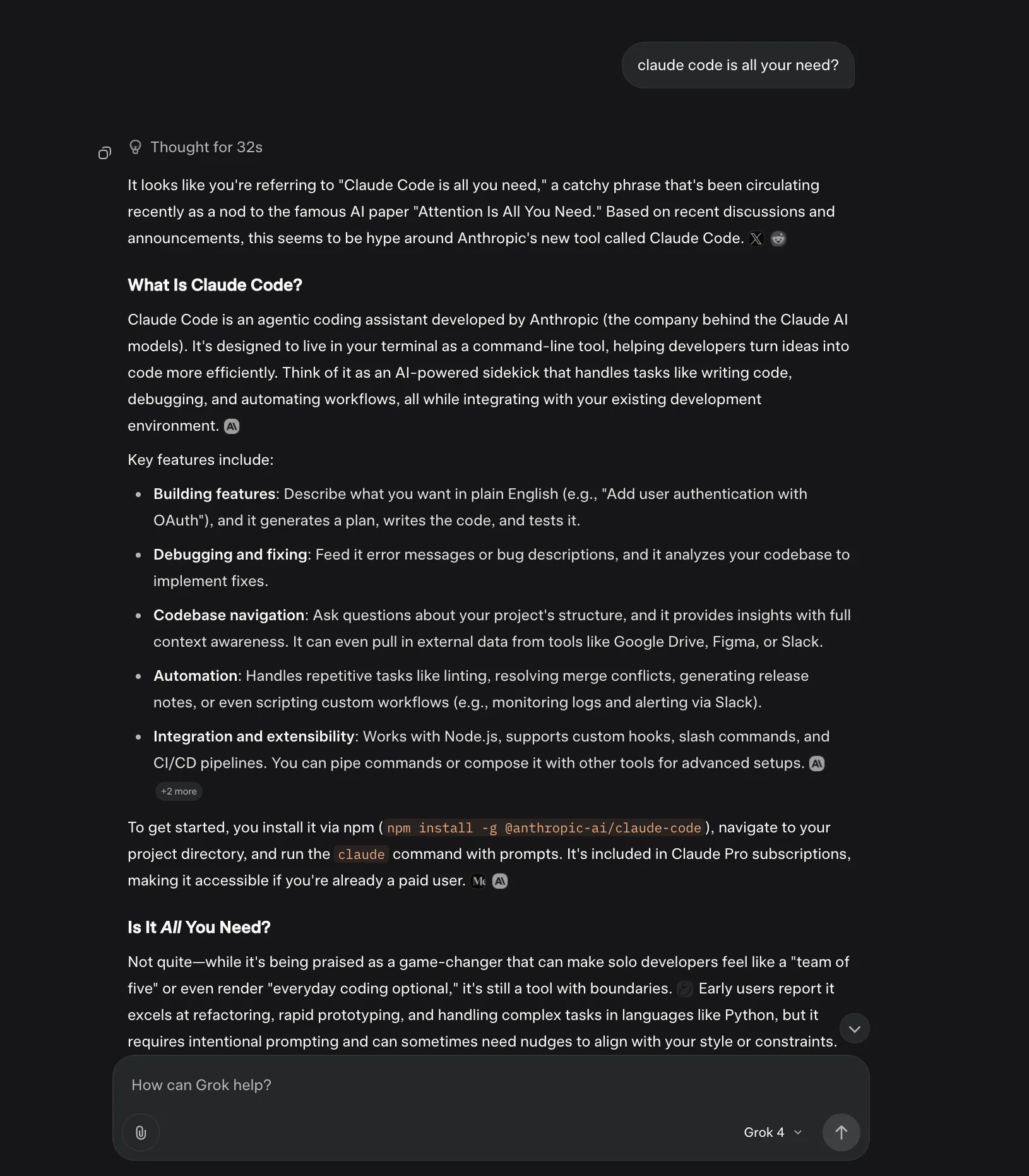
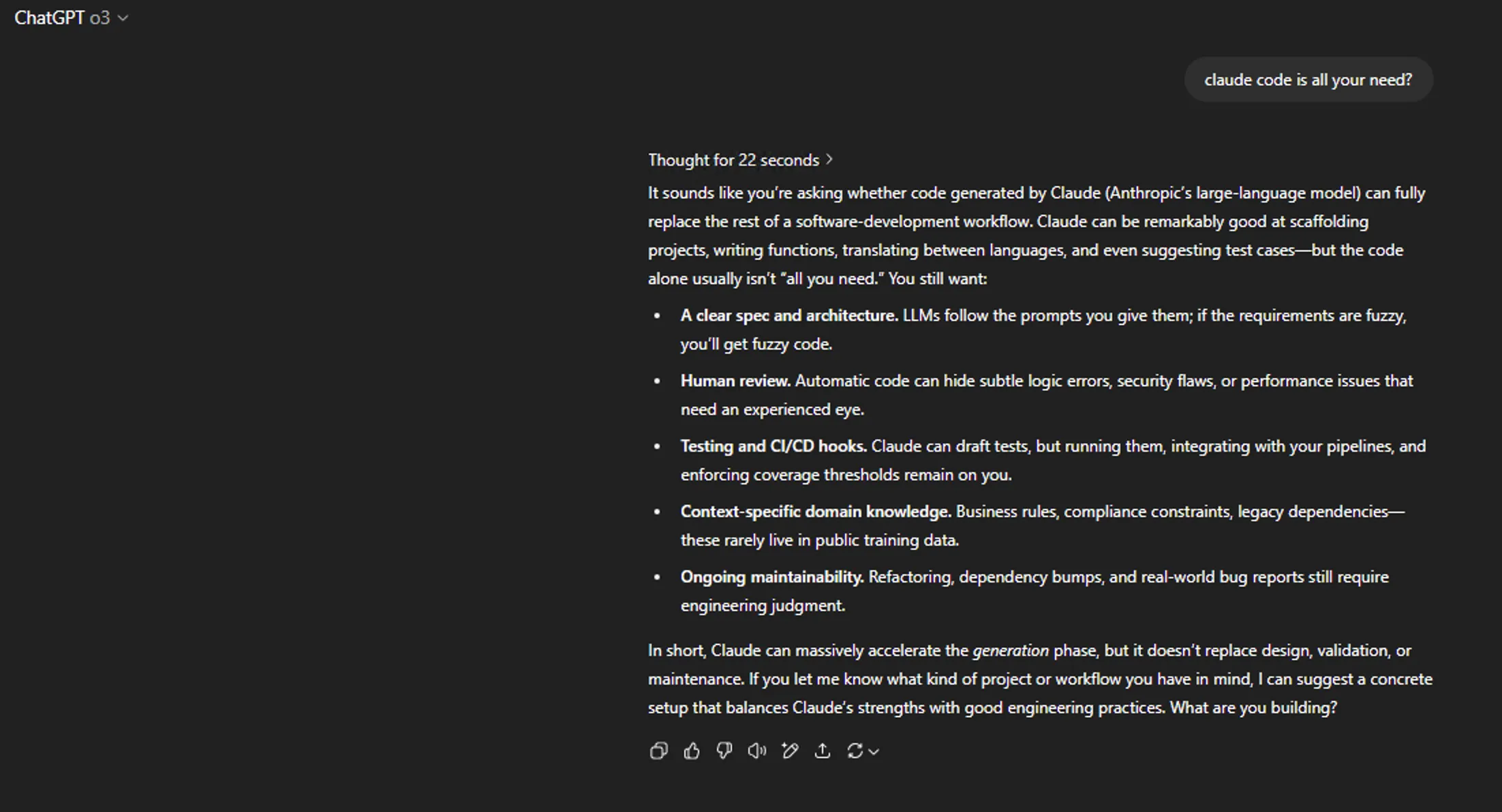
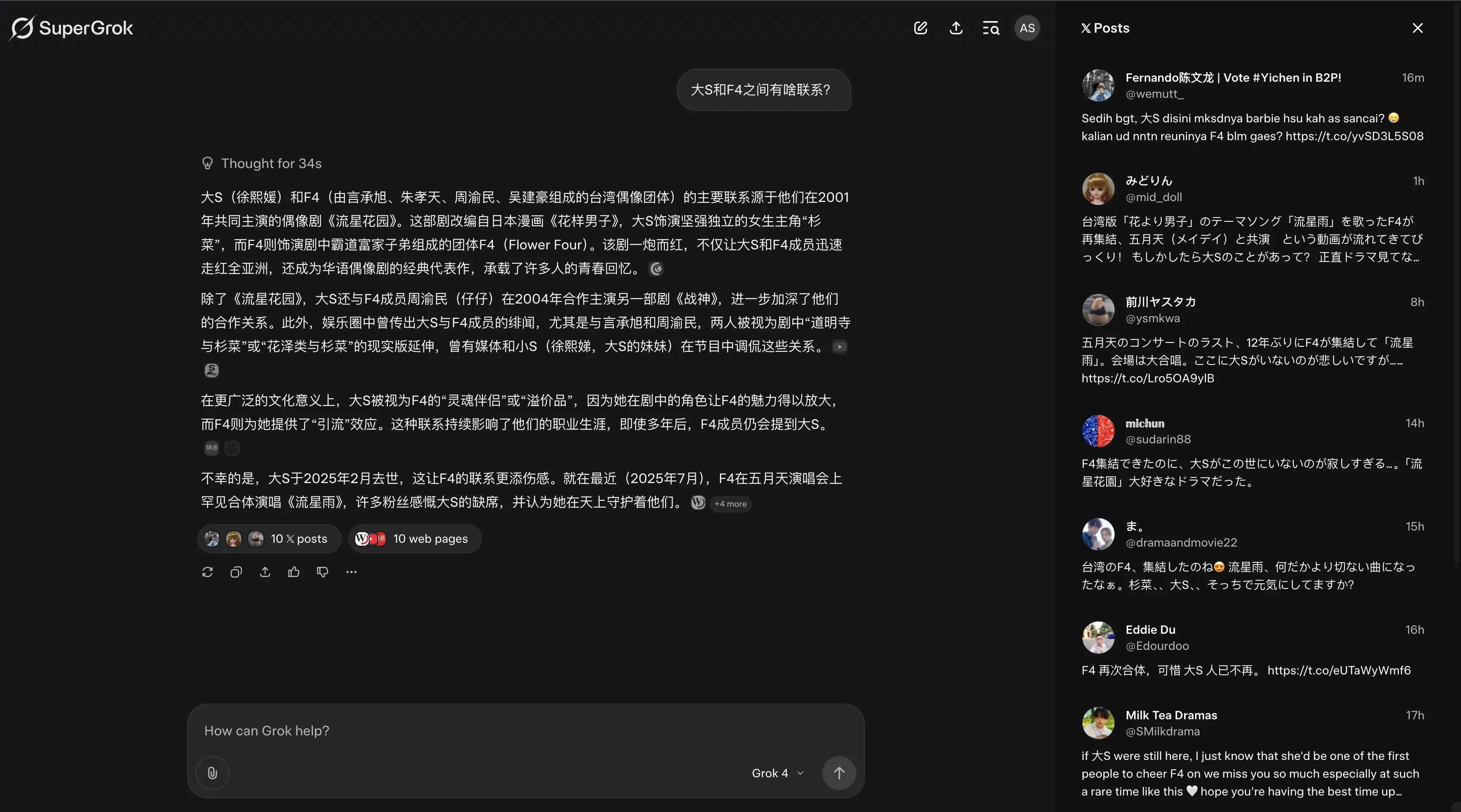
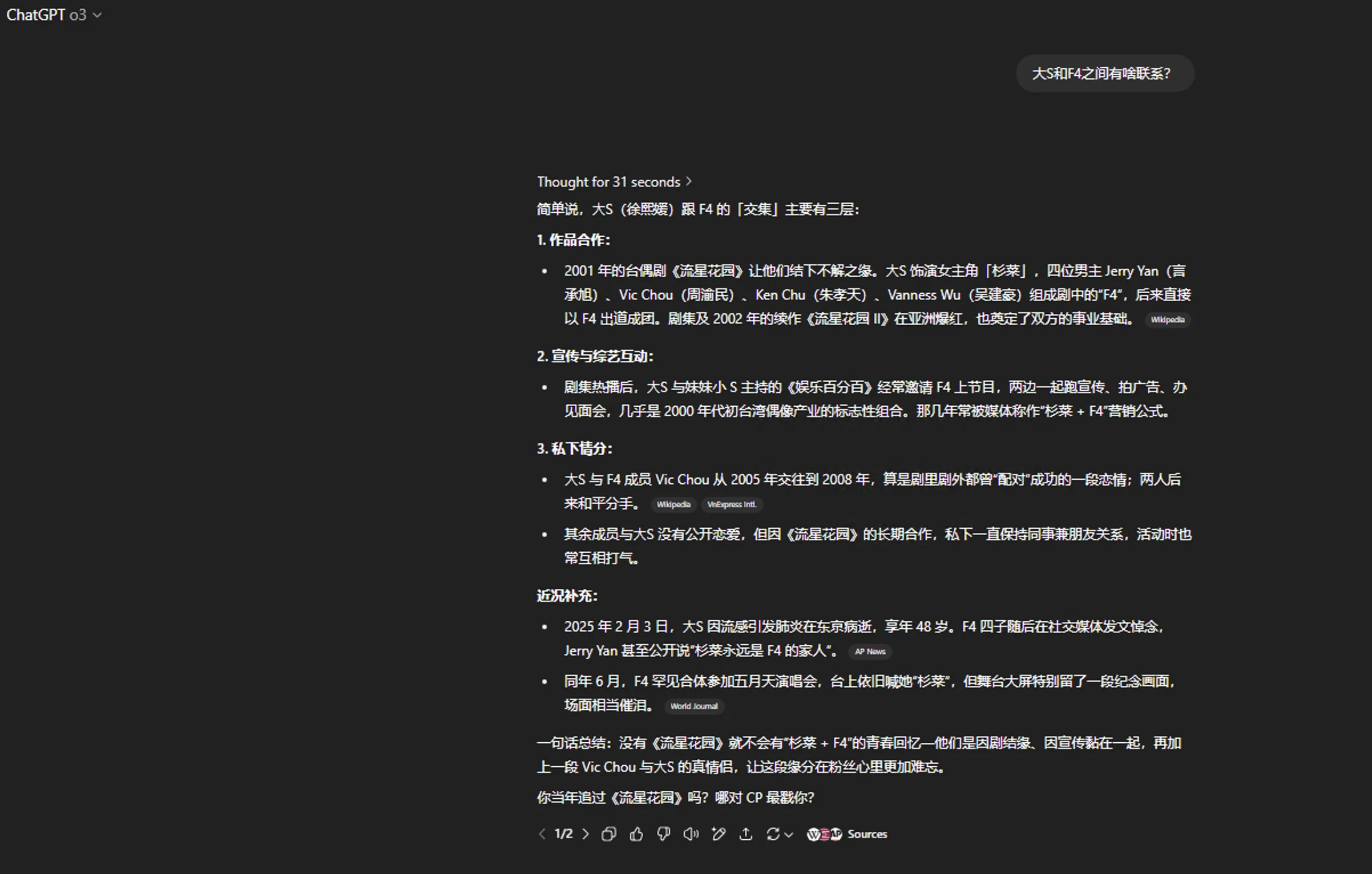
日常聊天交给Grok 4体验舒适,o3模型幻觉太高,看来下次让其事实核查我要更加多一个心眼了。下方展示了这种Agent LLM的对比。F4参加五月天演唱会是7月,o3误以为是6月,而Grok 4在时间方面表述准确。ChatGPT o3的回复给人的感觉就是机械式,这种段落结构式回复在日常聊天中是减分项,看看Grok 4的回复,这才是日常聊天需要的表述。还有一些例子见我的Mastodon账户。
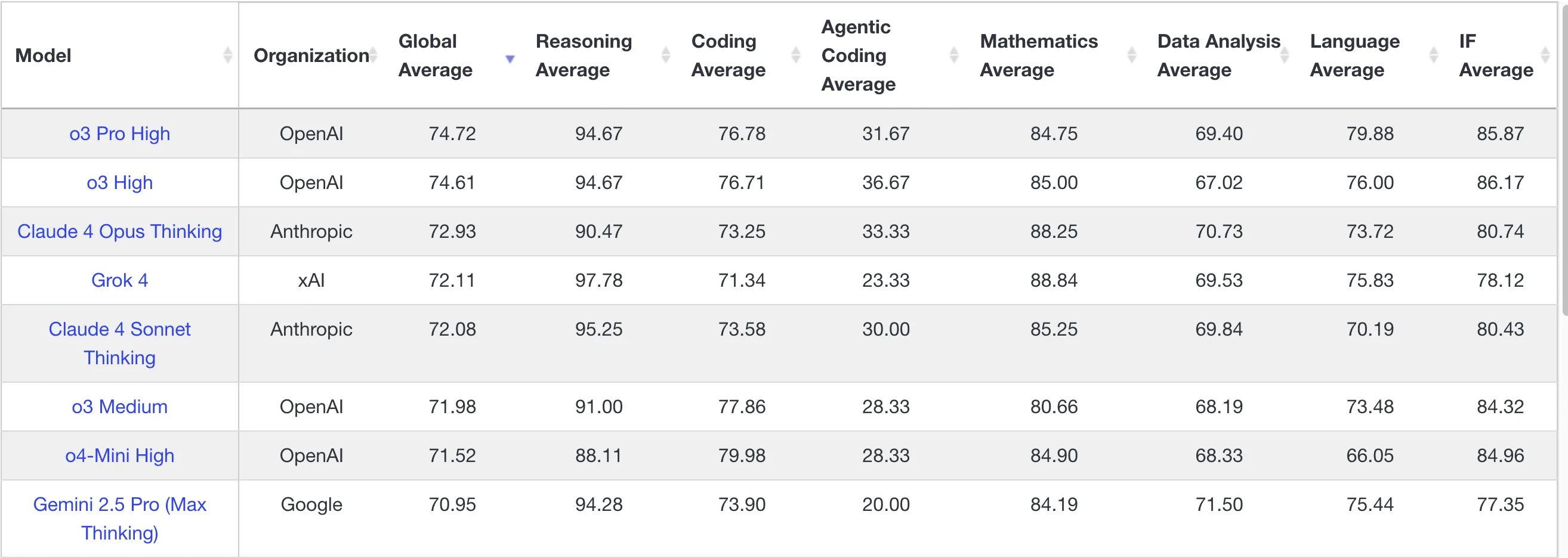
llm hallucination(幻觉)排行版:https://github.com/vectara/hallucination-leaderboard
grok 4幻觉率低于o3。
其实在Grok 3时代就已经能接入X posts了,只是当时我使用较少,基本上就2、3月份用Grok3,4、5、6、7基本上没用Grok 3,我的Super Grok两个月学生优惠就是空闲了2个月,基本没碰,毕竟当时的Gemini、ChatGPT、Claude风头太盛了。
Grok 4 Agent LLM和Grok 3 Thinking相比给人的感觉就是Grok 4 Agent LLM是真的根据用户需求,调用各种工具、反思,循环迭代直至完成任务,愈发觉得思维链太复杂没必要,展示关键的思维摘要,给人感觉就是真人在思考,这样子的Agent产品绝对比带思维链的推理模型强太多了。